TinyAnimal: Animal Recognition Practices on Grove Vision AI
Posted February 20, 2023 by joinbase0 ‐ 9 min read
In the TinyAnimal project, I will present the practices of EdgeML on the real-world cheap edge AI hardware.
The wild without a reliable internet connection
Story
Problem
There are many projects focus on the hardware of edge AI/ML. However, in real scenarios, there is no significant practice of learning details in software side on top of products to show, and this paper makes up for this deficiency.
At the same time, this project provides a complete and reproducible work flow of EdgeML/TinyML for animal recognition on one cheap edge AI hardware, which is rare in existing projects as known.
Hardware

Wio terminal and Grove AI Module in SenseCAP K1100 kit
The project's hardware is the Grove Vision AI Module in Seeed SenseCAP K1100/A1100. There is standalone version of Grove Vision AI Module in the official store.
The Vision AI Module has a chip: Himax HX6537-A. The mcu on the chip is based on the ARC arch which is unfamiliar to consumers. The main frequence is 400Mhz which is also not high. But the most interesting that the HX6537-A, has fast XY SDRAM memory architecture to accelerate the TinyML, like tensorflow lite model inferenece. We will see the performance of this chip later.
Workflow
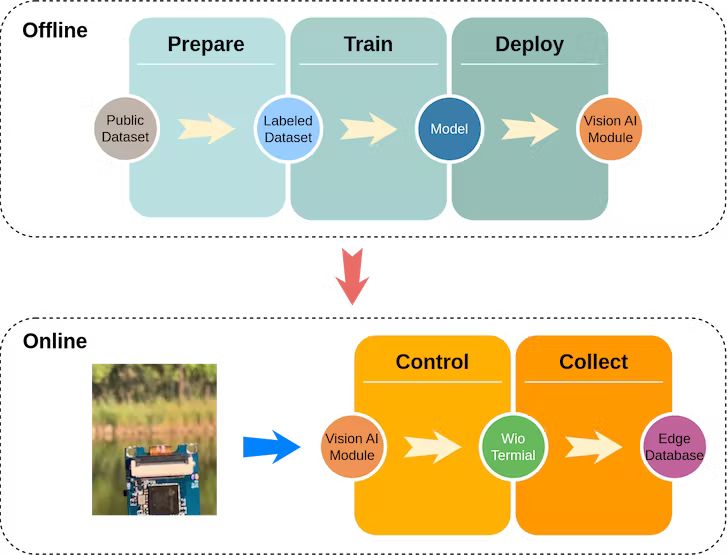
Workflow for TinyAnimal
The above workflow is common and clear. We only discuss some interesting requirements:
- The dataset is the public dataset with 9.6GB images.
This avoids the common problem of too few samples or insufficient representativeness.
- The training is completed locally.
This avoids the common problem of too few samples or insufficient representativeness.
- The data collection and realtime analysis is done via an edge database JoinBase.
Unlike the common databases like PostgreSQL or TimescaleDB, the JoinBase accept the MQTT message directly. Unlike the cloud service, the JoinBase support run in the edge which can be used in an environment without a network. Finally, the JoinBase is free for the commerical use which is also nice for further development of the edge platform.
Prepare Dataset
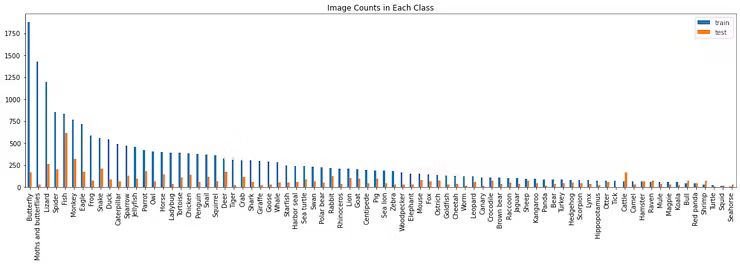
Overall of "animials-80" dataset
At present, there is not much public research on the workedge AI for wildlifes or animals. One of the few publicly available animal datasets - Animals Detection Images Dataset from Kaggle (called "animials-80" dataset ) has been used. It contains 80 animals in 9.6GB images, and should be great enough for common animal recognition task.
Prepare Training Data
The good thing of animals-80 dataset is that it has been labeled itself. But the original label format is not Yolov5 label format. A preparation work has been carried on it. The core part is the preprocessing function shown above. Please the later code repo for more.
Train
Because we don't have enough resources to do a full training on full 9.6GB training. So, a picked subset of animials-80 dataset has been choosen.
- 15-animal Subset Training
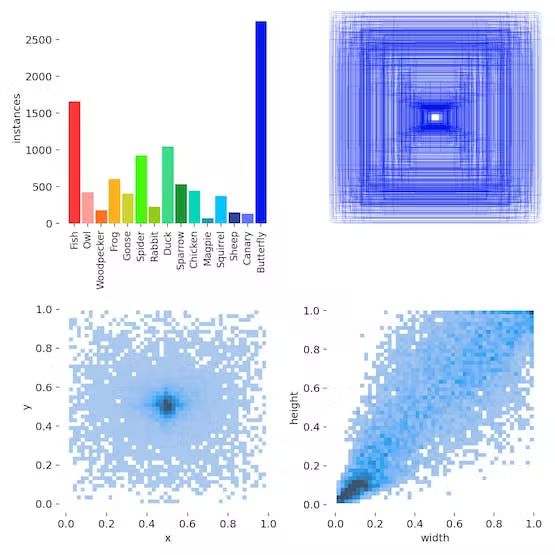
15-animal subset training
We use a 24c/48T Xeon Platinum 8260 Processor to do the training using above the commands got from offical example.
python3 train.py --img 192 --batch 32 --epochs 200 --data data/animal.yaml --cfg yolov5n6-xiao.yaml --weights yolov5n6-xiao.pt --name animals --cache --project runs/train2
However, after two hours (Yes, it proves again that Don't use CPU to train even it is a top Xeon SP), the final recognition effect is found to be very poor.
The main metrics are very low: the precision is 0.6, the recall and mAP_0.5 are just around 0.3.
In fact, this result is close to not working.
- 4-animal Subset Training
Let's reduce the types of recognized animals to four: spider, duck, magpie and butterfly, which of course are the most common animals in a suburban wild area.
Note, to re-run the preparing script to generate correct data/animal.yaml.
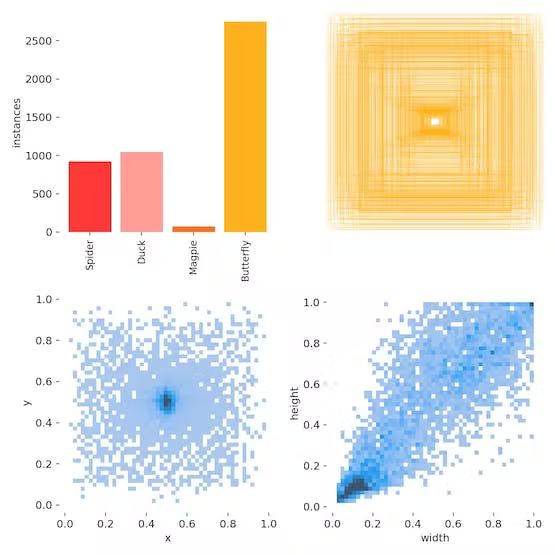
4-animal subset training
The main metrics become better: the precision is ~0.81, the recall and mAP_0.5 are around 0.6.
We will review the performance of this model in the late inference trials and evalutions. It is possible to do only a binary categorization: one animal and no animal. But in this project, I look forward to evaluating the recognition effect in more complex scenes.
- 4-animal Subset Training by YoLov5Official Pretrain Model
The above trainings are done by the Seeed's official document's recommend. The pretrained model is yolov5n6-xiao which may lack good generalization ability. In this project, we try a YoLOv5 official smallest pretrained model yolov5n6 to see whether there is some difference.
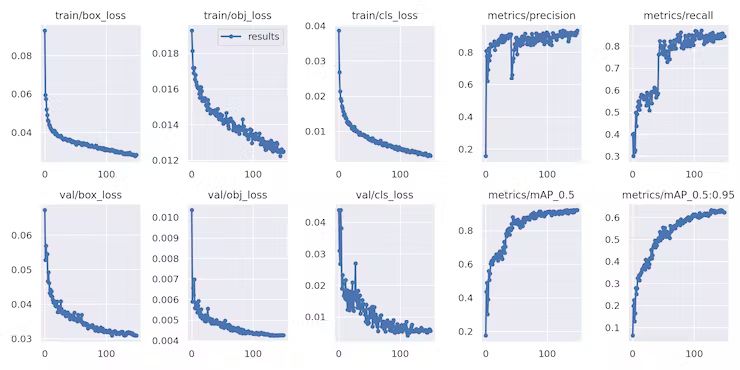
4-animal subset training with offical yolov5n6 model
The above result is obtained from the official yolov5n6 model with epochs=150. The result is great. Because,
The main metrics: the precision, the recall and mAP_0, 5 are all larger than 0.9. In the ML, the difference in mAP_0.5 between 0.6 and 0.9 is huge and huge in real-world detection.
Unfortunately, the final model trained based on the official yolov5n6 is close to 4MB, while the Grove AI module has the constraint model size no more than 1MB. So, we can not make use of any such bigger models (tried). Some suggestions will be discussed in the final section.Inference

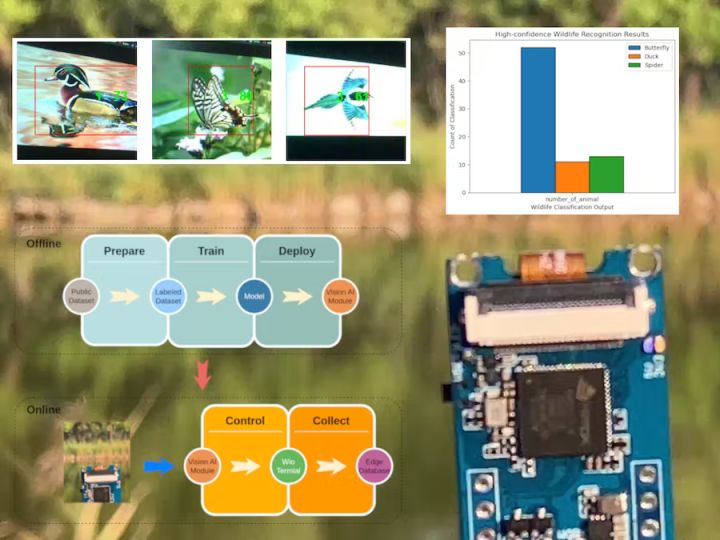
Three examples of detections in the simulation
After the above traning, we do a picture based simulation to preliminarily evalute the effect of the model. Let's see examples.
The above is the output of Grove AI module. The index of classification is in the middle and the confidence is around the side. The animal name of coressponding index can be seen in above training figures.
The first and second detection are right in a nice confidence and the third detection is wrong. The third picture shows a magpie fly in the sky and the inference result is the butterfly. We just see the impact of this classification model in the later real-wprld evalution.
Real-world Evaluation
Inferencing in real world is more challenging than inferencing in laboratory. Because the environment or the status of the tester or the tested object under the test can all have a big impact on the results. That is why we are planning in the workflow section.
We have done a real-world evaluation via a country park wildlife survey in the project TinyWild. Two types of detections are carried out:
- Dynamic Viewport (Moving Camera) Based Detection
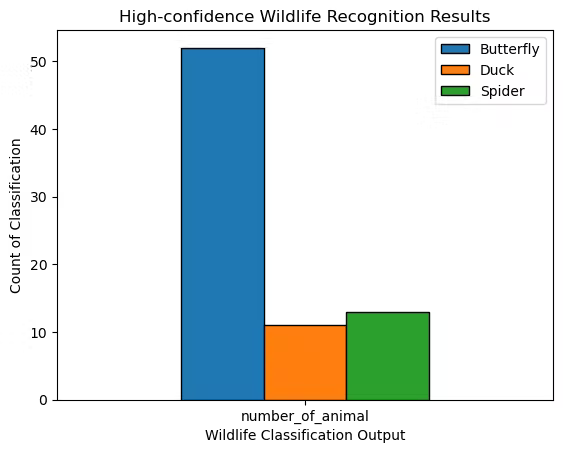
Classification statistics (with confidence > 75) in the whole survey
The above figure is the classification statistics (with confidence > 75) in the whole survey. There is a large time in which the camera is moving. So, this is a dynamic viewport (moving camera) based detection. "Unkown" and empty animal which stems from the software logics has been excluded here.
The basic conclusion is that, for individual identification, it is not particularly ideal, but the qualitative information collected is effective.
Bufferfly is relatively outstanding in the statistics but without Magpie that've seen many times in the park.
This seems the Magpie are been recongized as the bufferfly as shown in the analysis of the Inference section above. What they have in common is that, they often flys in the air. Three real-world factors: moving camera, moving objects and low resolution, have a great impact on the recognition results.
- Static Viewport (Static Camera) Based Detection
To reduce impact of moving factors, a dedicated wild duck (mallard) observation in the lakeide has been carried out as well.

Primary process of the static wild duck observation
In the above first of captures, the count of duck in our frontend UI (one of interesting in this is that the dynamic table in UI is driven by a SQL query, please see our more infos in future projects) is 10. Suddenly, two ducks swims into the scope of camera. The count of duck has been increased to 13. Considering the orignal duck is counted, the 13 is the exacting count at that moment. It is found that the Grove AI works greatly for nearby animal detection like we done in lakeside: we got three counts when suddenly three ducks swims into the scope of camera in a relative static positioning. (note: in the TinyWild project, we said there are four counts, but it should be corrected to three counts according to our recordings.)
Ideas
Based on the above pratices, we give out the following suggestions for EdgeML or TinyML on a cheap edge AI hardware:
- Try to observe statically
i.e. observers do not make large movements.
- Detect as few objects as possible
For example, only do the binary categorization: people or nobody, monkey or no monkey, bird or no bird.
- Make main metrics of model as large as possible
For example, the precision > 0.8, the recall and mAP_0.5 > 0.6.
- Improve recognition accuracy as possible (like, longer training time)
The cheap edge ML hardware usally has the limited resources, for example, Grove AI module has the constraint model size no more than 1MB, which falls below the model size trained from the yolov5's official yolov5n pre-trained network. The smaller model is found to significantly affect the model's primary metrics.