JoinBase: Creates An Unprecedented Database for IoT era
What's JoinBase
JoinBase is an end-to-end database database for IoT. With it, you can do top performance real-time analytics over massive IoT device's bigdata deluges at an extremely low cost in one stop.
More information of JoinBase is around the website.
Benchmark
In this article, JoinBase and interesting peers (Timescale and ClickHouse now) will be benchmarked.
Since there is no suitable benchmark program to bench the new end-to-end database for IoT, we built an open source project for benchmarking ourselves. This is, just the "Open IoT Database Benchmark Suite" (OIDBS), which we have open-sourced into the community.
Benchmark Model
The core of OIDBS is the benchmark model, which is used for grouping different benchmark dataset and its corresponding data-gens, schemas, queries.
In the first launch of JoinBase and OIDBS, two models - 'nyct_lite' and 'nyct_strip' are benched:
| model name | model dataset size | description | how to get |
|---|---|---|---|
| nyct_lite | 10906860 rows | New York City Dataset used in official Timescale (compressed in one 424MB file) | Timescale Docs |
| nyct_strip | 1000000000 rows | Extended 1-billion-row New York City Dataset with stripped columns (compressed in 13GB files) | download pre-made from mediafire or prepare from this github project |
Tab.1 OIDBS models introduction
These two models are derived from official, real-world New York city dataset. The nyct_lite is relatively small dataset, but it is exactly what Timescale uses to demonstrate its application in the IoT field.
The importance of nyct_lite model is that:
- the dataset, schemas, (parts of) queries in this model are all from Timescale. So, obviously, we can't lower the performance of our competitors by picking specific dataset, schemas, or queries. As an open benchmark suite, we clearly reject this practice that is indeed common in other benchmarks.
- because the size of
nyct_liteis relatively small, it is a great real-world dataset to understand the performance situation for the edge case and the short-term IoT data analysis and monitoring scenario.
The nyct_strip could be seen as the bigdata version of nyct_lite. We extract 1 billion rows and 7 representative columns from the around 1.7 billion rows and 27-column original schema to form a stripped dataset. The size of the original is too large to reproduce (compressed 600GB+ csv). For users, it makes non sense to claim that any result on non-reproducible dataset.
The importance of nyct_strip model is that: the big data scenario is the standard situation for most IoT businesses.
Setup
| Item | Description |
|---|---|
| Hardware | 2 AWS EC2 m6a.16xlarge instances (1 server, 1 client) with 600MB/s EBS gp3 volume |
| OS | Ubuntu 2022.04 LTS with C-states and Turbo Boost disabled |
| JoinBase | Enterprise 2022.04 |
| Timescale | Postgresql 14.3 with Timescale extension 2.6.1, Timescaledb-tune 0.12.0 (the latest from official download) |
| ClickHouse | ClickHouse 2022.5 (the latest from official download) |
Tab.2 Setup for the benchmark
Timescale and ClickHouse are selected as the comparing group in this benchmark. We think these two are the representative DBMSs in TP and AP fields respectively. Indeed, many other products that claim to outperform these two. But based on our testing or knowledge, we don't think they deserve to be included in this benchmark.
By comparing with these two state-of-the-art DBMSs, we hope to show interesting and profound conclusions, and finally why JoinBase is the unique product to cover the full payload spectrum for IoT domain in the world.
AWS m6a.16xlarge instance uses AMD 3rd generation EPYC CPU. We think it is relatively modern hardware. However, the vCPU counting of m6a.16xlarge is quite restrained in that the upcoming Zen4 based EPYC will have up to 256 hyper-threads.
C-states and Turbo Boost have been disabled in the formal benchmark. The c-states switching and boosting causes obvious run time fluctuations. Furthermore, in a highly concurrent production environment, there is no possible to boost for busy cores unless your software much under-utilize the CPUs. The boosting is just one pitfall of the micro-benchmark, which could be seen in benchmarks before.
Last, we use the latest available versions of all softwares to make sure all benched peers are in the officially best condition.
Performance Comparison - Write side
The write side benching should be one of the most interesting bench points. However, due to that there is no true IoT messaging native domain database except JoinBase. An apple-to-apple comparison can not be done, indeed.
Here, we just give out the world record level performance data of JoinBase and some observations on other benched dbs.
| DB | Model | Batch Size | Threads * Connections | Elapsed Time (in seconds) | Million messages/s |
|---|---|---|---|---|---|
| JoinBase | nyct_lite | 1 | 1 * 1 | 27 | 0.4 |
| nyct_strip | 1 | 50 * 1 | 446 | 2.2 | |
| internal stress 2 columns, 12B/row | 1 | 64 * 32 | n/a | 8.4 | |
| internal stress 10 columns, ~90B/row | 1 | 64 * 32 | n/a | 1.8 | |
| Timescale | nyct_lite | 5000 | 1 *? | 189 | 0.06 |
| nyct_lite | 5000 | 16 *? | 25 | 0.4 | |
| nyct_lite | 5000 | 32 *? | 25 | 0.4 | |
| nyct_strip | 5000 | 16 *? | 465 | 2.1 | |
| nyct_strip | 5000 | 32 *? | 408 | 2.4 |
Tab.3 Setup for the benchmark
Note,
- For the elapsed time in importing, we use the best value in the whole one-week bench period.
- JoinBase's importing in OIDBS only uses one file per thread/worker concurrency, this will lead to
nyct_lite,nyct_stripexternal model has not enough client concurrency. - JoinBase uses MQTT based one-by-one message importing. But, for Timescale, OIDBS uses external timescaledb-parallel-copy tool to import csv, it does batching in its own way. Otherwise, the import speed of Timescale will be too slow to complete the import of
nyct_stripbigdata. - Due to no convenient way to do multi-thread network based data ingestion for ClickHouse, we do not include the data of ClickHouse here. But, generally, it is quietly slow if the naive, local clickhouse-client based csv importing used in our experience.
- In the internal stress of JoinBase, we use a fixed time period, for example 100s, so just the MPS(Messages Per Second)s are cared and shown in these rows.
- We don't know and are not interesting in how timescaledb-parallel-copy handle the connections, so the item for Timescale importing shows as
?. - One interesting thing: we observe that Timescale needs too long time to drop a new ingested large table.
The most exciting thing is that, JoinBase importing uses the MQTT based one-by-one messaging. One-by-one messaging capability is a unique IoT domain demands, and should a must for any database call itself "database for IoT". Any client-side batching mechanism comes at the cost of increased latency and thus increased risk of unresponsiveness, which should be unacceptable for IoT users.
In our internal stress, 8.4 million messages/s sustained throughput in one-by-one message (a.k.a. batch size = 1) importing can be achieved in JoinBase. Although Timescale also has a good result when batching enabled in client (the timescaledb-parallel-copy tool here), the first version of JoinBase still crushes it with enough concurrency in one-by-one style.
update (2022.12):
In the initial release, JoinBase does not support batched message ingestion. This has changed after 2022.11. With the batch ingestion support, JoinBase can reach a sustained throughput of 25 million messages per second (50 msgs/batch, 40 bytes/msg), and this is not the maximum value, as at this point our NVME SSD(WDC PC SN730)'s continuous write (out-of-buffer) bandwidth (avg ~1GB/s) has become saturated!
Performance Comparison - Query Latency
The benchmark item to query latency is used for measuring the response time to a single query.
In the benchmark, we run three times per query and uses the best run time among three as the final result. It is nice to pick up the best result because a system may need some warmups for queries, e.g. cache, decompressing. Pay attention that we are benching serious DBMSs for massive data not in-memory toys.
For 10-million-row level nyct_lite model, 8 queries has been proposed. Among of them, both the seventh and eighth queries are taken as-is from Timescale itself's document - Introduction to IoT: New York City Taxicabs. (All other queries in this document are multi-table queries a.k.a. joins. We will add these queries to the benchmark in the near future when JoinBase's high performance join implementation coming.) See more detailed SQLs in our OIDBS source.
| No | Query description for nyct_lite model |
|---|---|
| 1 | get row counts of whole dataset |
| 2 | get all passengers |
| 3 | get all total amounts |
| 4 | get average passengers for every payment_type |
| 5 | get all big-trips passengers by 3 dimensions |
| 6 | get 4 aggregations by 3 dimensions |
| 7 | How many rides of each rate type took place in the month? |
| 8 | What is the daily average fare amount for rides with only one passenger for first 7 days? |
Tab.4 Queries in the `nyct_lite` model
Note,
- Due to the time limitation, the ClickHouse bench is done by manual. The related scripts could be seen in the OIDBS project here. We continuously issue many times (>= 10 times) in clickhouse-client and record the best/shortest run time. It has been observed that the fluctuation of ClickHouse's run time is very large. But because we just record the best one, it is believed that this does not affect the results.
- For JoinBase and ClickHouse server, we just use the default configuration. As we are good at the two databases, it is believed to be best for both. For Timescale, the timescaledb-tune tool is applied according to the official document. It is interesting that, we see +92% (Q2) to -92% (Q5) speedup by applying the timescaledb-tune. Yes, it is not always a positive speedup. For the Q5 query, a strong slowdown occurs. But generally, we still observe ~20% improvement in the run time.
Jump to the result!
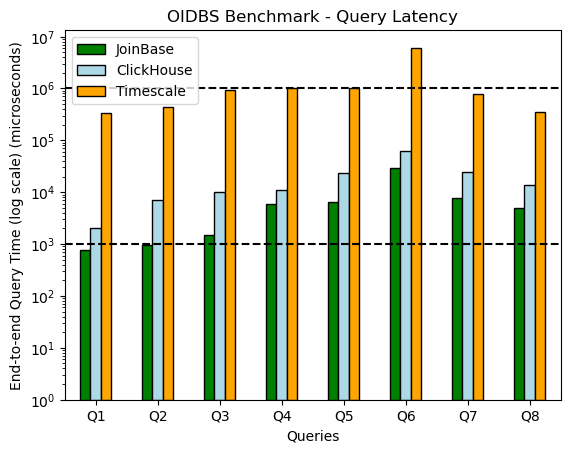
Fig.1 Query latency benchmark results for nyct_lite
| Elapsed time ratio | ClickHouse:JoinBase | Timescale:JoinBase |
|---|---|---|
| Q1 | 2.567394 | 430.758665 |
| Q2 | 7.179487 | 447.198974 |
| Q3 | 6.7659 | 620.227334 |
| Q4 | 1.836394 | 170.585309 |
| Q5 | 3.568658 | 161.378123 |
| Q6 | 2.201796 | 212.638171 |
| Q7 | 3.136025 | 102.999477 |
| Q8 | 2.822012 | 70.489821 |
Tab.5 Elapsed time ratios of ClickHouse to JoinBase and Timescale to JoinBase
Fig.1 is the query latency benchmark results for nyct_lite. We use the log scale in end-to-end query time(y axis) because the gap is 2 to 3 orders of magnitude! The specific ratios of the query time to that of JoinBase are shown in Tab.5. Additionally, two lines are put at 1 millisecond and 1 second for better quantitative understanding. Let's just summarize the exciting in results:
- From the average query latency/speed, The JoinBase is 70x to 430x (276x in average) faster than Timescale and 1.8x to 7.2x (3.76x in average) faster than ClickHouse.
- The latency of Q1 and Q2 in JoinBase is in the microsecond level. Yes, JoinBase claims to be the first database to do the 10-million-row' sum aggregation in microseconds.
- The max latency of JoinBase for
nyct_lite, is 28 milliseconds. In contrast, 87.5% of ClickHouse's queries are around 10 milliseconds and above, not mention that of Timescale. - The speedup of simple aggregations (Q1 - Q3) in JoinBase is obviously larger than that of group-by aggregations (Q4 - Q8). Because this is the first version of JoinBase, there are several important optimizations we haven't applied yet to group-by aggregations. Stay tunned!
- Again, Q7, Q8 are the as-is queries from the Timescale's document. Welcome to reproduce them yourself.
For 1-billion-row level nyct_strip model, 6 queries has been proposed. Although the nyct_strip model has fewer columns than that of nyct_lite, these queries are still tweaked from nyct_lite.
| No | Query description for nyct_strip model |
|---|---|
| 1 | get row counts of whole dataset |
| 2 | get total passenger counts |
| 3 | get stats of main metrics(main metrics' max, min, avg) |
| 4 | get all big-trip passengers by vendor_id and cab_type |
| 5 | group 3 metrics by 3 dimensions |
| 6 | What is the daily average total amount for all rides? |
Tab.6 Queries in the `nyct_strip` model
The benchmark process of the nyct_strip model is same to the nyct_lite, except that we use the different dataset and query set.
Go to the results:
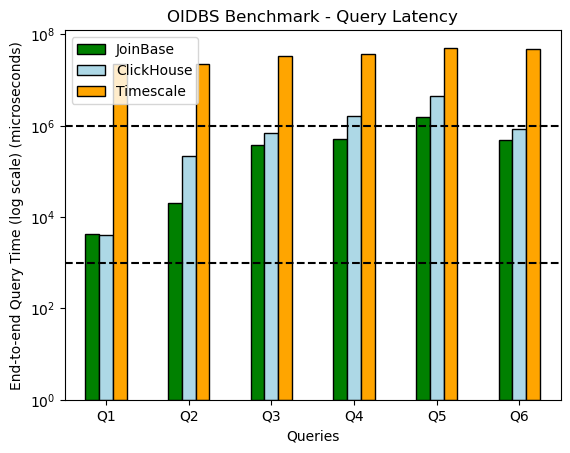
Fig.2 Query latency benchmark results for nyct_strip
| Elapsed Time Ratio | ClickHouse:JoinBase | Timescale:JoinBase |
|---|---|---|
| Q1 | 0.957625 | 5274.373713 |
| Q2 | 10.487293 | 1107.034925 |
| Q3 | 1.802263 | 87.607608 |
| Q4 | 3.091635 | 72.883191 |
| Q5 | 2.815859 | 32.127069 |
| Q6 | 1.7338 | 94.253238 |
Tab.7 Elapsed time ratios of ClickHouse to JoinBase and Timescale to JoinBase
The nyct_strip 1-billion-row dataset are more challenging, but when our IoT devices scale out, we have to face.
From the average query latency/speed, The JoinBase is 32x to 5274x (1111x in average) faster than Timescale and 1x to 10.5x (3.5x in average) faster than ClickHouse.
The latency of 83.3% queries of JoinBase are below 500 milliseconds. JoinBase claims to be the first database to do the 1-billion-row complex aggregations in sub-second level. In contrast, 66.7% of ClickHouse's queries are around 1 second and up to 4.4 seconds, not mention that of Timescale.
Due to the precision of ClickHouse's response time is only down to milliseconds. For the Q1 query, JoinBase's time 4.177 milliseconds, ClickHouse's is 4 milliseconds. It is thought that, on the Q1, two are in the same level.
There are two trends from small to big dataset:
for simple aggregations, the ratio becomes larger (10x to ClickHouse) and larger (5000x to Timescale). This shows we have an excellent, strong and unique implementation for our simple aggregations.
for group-by aggregations, the ratio becomes smaller. This hints that there is a great improvement space for the memory sized big data set.
The reasons for the trend is mainly at the algorithm's implementation. We will discuss the reasons in depth in the technical blog in the appropriate future.
Performance Comparison - Query Concurrency
The benchmark item is for measuring how many the alert trigger queries to recent data can be completed per second.
This benchmark item is very exciting to demonstrate the uniqueness of JoinBase. When IoT devices scale, not only the incoming data goes big, various types, locations, measurements of data come in as well. In other cases, for the big enterprise or organization, kinds of queries to recent small data set will aggregated. Users always want to customize many alert trigger queries for the latest data. Note, for this case, the caching trick is useless, because the recent data is always changing in production and we want to know the newest result as possible.
For simplicity, we propose a specific alert like query to use the latest time period as the query interval, like this:
| DB | Query |
|---|---|
| JoinBase | select count(total_amount) from nyct_lite where parts 2016013112 where total_amount<0 |
| Timescale and ClickHouse | select count(total_amount) from nyct_lite where pickup_datetime>='2016-01-31 12:00:00' and pickup_datetime<'2016-02-01 00:00:00' and total_amount<0 |
In this query, an interesting extension of JoinBase to ansi-SQL is shown. It is called where parts clause, which lets users to specify explicit partitions to the query. More details about partition and where parts could be seen in the documents. Because the nyct_lite dataset (from Timescale) has a very tiny tailing data happens in 2017, we use the latest data interval in 2016, that is half of the day in 2016-01-31.
This query imitates an alert query to report the counting of anomaly trips in the latest half of the day, here is of those the total_amount less than zero.
Go to the result:
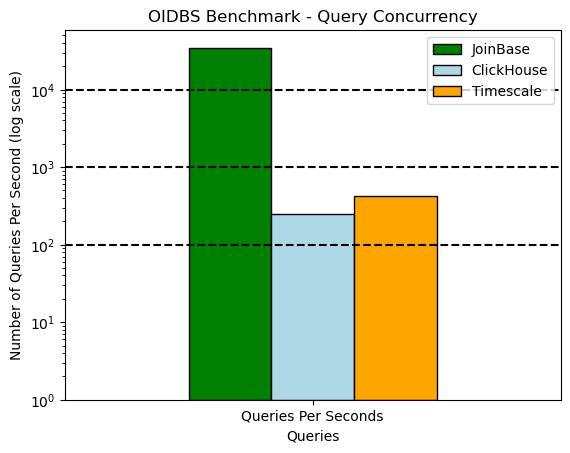
Fig.3 Query Concurrency benchmark results
| DB | QPS (Queries Per Second) |
|---|---|
| JoinBase | 34622.92128461751 |
| Timescale | 422.64208085668804 |
| ClickHouse | 245.23233571554584 |
As we can see, the QPS of JoinBase is two orders of magnitude higher than that of Timescale and ClickHouse. JoinBase's custom query path is so incredibly fast that it can complete 34k lightweight adhoc aggregations for recent data in a modern mid-range box. Even TP databases (see Timescale) are far from beating, not mention the AP system (ClickHouse).
Outlook
Some interesting things which can not be included in the first release of JoinBase, due to the implementation or time limit.
Benchmark updates when more performance improvement coming.
We just release the first version of JoinBase. There are many optimizations which we can do but not yet done currently.
More benchmark queries when join coming.
There is no doubt that JoinBase will continue to lead in the performance. Yeah, you can always trust JoinBase!
More robust benchmark system.
Some databases like to exploit the weaknesses of benchmark suites, which you may meet in one paper or another clickbait blog. We want to fix this problem for our users in the new OIDBS. For example, we are considering to introduce a random seed to the benchmark queries. Query result set caching is a cheat for analytical performance benching. Before fixing this, try some random perturbation to your query expressions when evaluating.
TPCx-IoT inspired model will come soon.
The model called 'pstation' is working in progress. Join the community if you are interesting to track on this.
Benchmarks on storage data sizes.
The modern storage is very cheap. The storage size in a single modern box can hold PB(Peta-Byte) level data. JoinBase is built for this. In fact, for almost all enterprises, their active data will not exceed this limit. So, we think this benchmark item is not really interesting for including in any hurry.
Benchmarks on ARM based processors.
JoinBase supports three main stream CPU arches from day 0. With recent AWS makes Graviton3 generally available in c7g instance, it are truly interesting to show how good the JoinBase works in this processor. Still stay tunned!
Conclusion
JoinBase is creating an unprecedented, user-oriented, end-to-end database for IoT:
- For all devices, JoinBase supports the small message, out-of-order but highest concurrent write.
- For recent data's monitoring, JoinBase supports the lowest latency, highest concurrent aggregations.
- For medium and long-term data analysis, JoinBase supports the fastest interactive SQL queries (in all implemented features).
- For the IoT domain, JoinBase supports MQTT message direct write, message payload mapping, device management, MQTT broker bridging, restricted resource and environment running, et.al..
Finally, welcome to request the JoinBase Enterprise for free.